Website content is still, and always will be, the backbone of search engine optimisation (SEO).
Your ideal customers find you through search engines based on content you have published, and the rankings are determined based on the content you’ve published on your blog. (And a ton of other factors!)
However, not all content is created equally.

Duplicate content has been a massive issue for brands and marketers for years, and is a discussed topic.
So this article is dedicated to duplicate content and its association with SEO along with best practices to minimise it!
Let’s get to the nitty gritty.
What is duplicate content?
Duplicate content refers to the similar content that appears on the same website or different websites. It includes exact copy and rewritten content that’s similar to another piece.
A simple examples of duplicate could be a blog post that you republish on Medium from your own account (at least without a proper canonical tag pointing to the original source).
Similarly, if a single web page is accessible via two different unique URLs on your website, such pages are considered duplicate.

Header, footer, and other parts and sections of your website that go with every webpage don’t count towards duplicate content as long as they are part of the website’s structure and navigation.
Duplicate content falls into two categories:
- Exact copy of the content e.g., a single blog post published twice (mistakenly) and accessible via two unique URLs
- Similar content that’s not word-to-word copy but is highly similar.

Google Ads tips
Learn advanced tips that PPC professionals use to dramatically increase their Google Ads performance!
How does duplicate content affect SEO?
Duplicate content affects SEO in multiple ways which makes it concerning for businesses, marketers, and SEO consultants alike.
Before we jump into SEO issues that duplicate content have on your site’s ranking, it’s important to understand the types of duplicate content:
- Same domain duplicate content
- Cross-domain duplication.
Having similar or the same web pages across your domain is more concerning than having an exact copy of your article published elsewhere on the web (known as content syndication).
So, why is having duplicate content an issue for SEO?
There are a few reasons:
1. Missed rankings and poor UX
Google prefers indexing and ranking distinct pages with unique content. If you’ve duplicate content on your website, Google will rank the most appropriate web page (which might not be the version you want to rank for).
This creates poor UX as organic traffic might be directed to a page you haven’t optimised for visitors or linked internally.
Here’s how Google explains this:

2. Self-competition
This is a more severe SEO issue where you compete against your own content which means low organic traffic. This is more problematic for duplicate content across domains because Google might rank syndicated content higher than the original source.
For example, the following article was published originally in Inc.com by the author and then later republished on Medium:

Here’s the original article:

The author reworded the republished content slightly by changing a few words, but overall, the theme and structure of the republished article are quite similar.
End result?
The traffic is divided and both articles rank in SERPs:
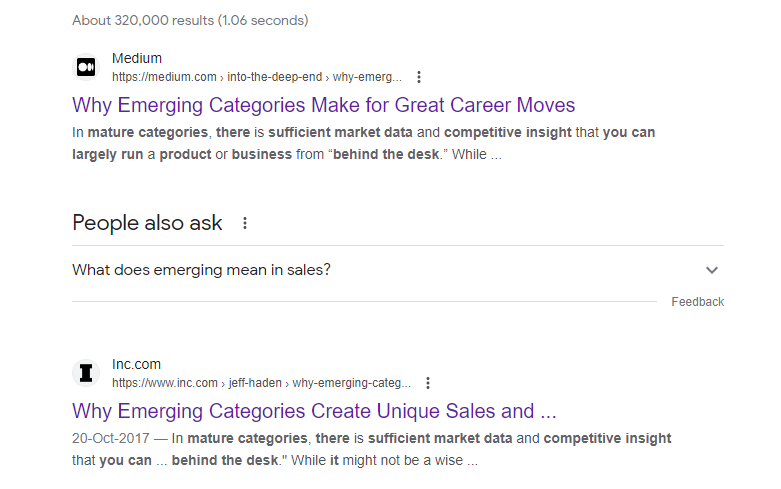
Interestingly, the duplicate content is outranking the original content. This isn’t something that most authors want as it diverts traffic from the original site. Here’s the thing…
Duplicate content creates self-competition in an event when both (or all) versions of the content (same site and cross-site) start ranking and this leads to a significant loss of organic traffic and creates another issue…
3. Indexing issues
Google allocates a certain crawling budget to each website. Googlebot visits your site to crawl existing and new pages to monitor changes and there is a certain bandwidth that is allocated per site (which can be viewed in Search Console).
Websites having several duplicate pages require Googlebot to crawl all the duplicate pages and this leaves less time and resources for newly published pages. If your crawl budget is exhausted, you might struggle to index new pages. This issue is more common with bigger sites having hundreds and thousands of URLs.
Inefficiencies in crawling are a serious issue for certain websites such as news sites and seasonal sites where the life of the content is very short and if it doesn’t get indexed on time, it becomes worthless.
4. Penalty
Duplicate content penalty is rare, but Google doesn’t deny it.


If you are deliberately duplicating content, you might face consequences in the form of a penalty. In that case, your site might get de-indexed completely from SERPs and Google might refuse to index any new pages you publish.
That’s a complete removal from SERPs 😲.
Further Reading
Duplicate content best practices
Duplicate content affects SEO, brand credibility, and UX.
You not only have to make sure that you aren’t publishing duplicates on your website, but you also have to make sure your content isn’t being scrapped and republished (without your permission) by other sites.
Here’s a list of the best practices to effectively fix, manage, and avoid duplicate content on the same and different domains:
1. Use a canonical tag
A canonical tag is an HTML code that helps you tell search engines the primary or original version of the content. It instructs the crawlers to crawl, index, and rank the right version in SERPs.
Here’s how canonical tag is used:
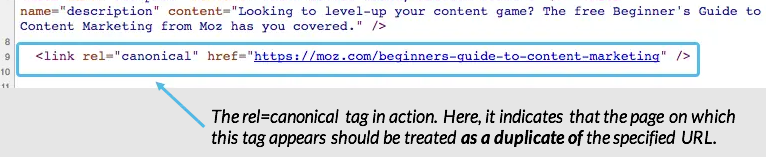
When you’ve duplicate content across multiple URLs, using canonical tag helps you index the right copy that you want to rank:

The use of proper canonicalisation is the recommended way to deal effectively with same domain and cross-domain duplicate content.
Even if you don’t have duplicate content on your site, it is a good idea to use a canonical tag to define the main page in case you end up creating a duplicate page mistakenly (which happens a lot in cases such as search parameters for ecommerce stores and categories for blogs).
Canonical tags ensure that the right version ranks in SERPs and you don’t end up exhausting your crawl budget.
Google Ads tips
Learn advanced tips that PPC professionals use to dramatically increase their Google Ads performance!
2. Use redirects
Redirecting web pages to the original version is another way to get rid of duplicate content.
Using 301 redirect tells the search engines that the page has permanently moved to the new location. Visitors and crawlers will always be guided to and see the correct, intended version of your content:

In case of redirect, the duplicate web page isn’t visible to anyone. This is what makes redirection different from a canonical tag. The duplicate pages in case of using canonical tags still exist and are visible to both crawlers and humans.
Redirects are suitable when:
- You know the exact URL of the duplicate page
- Duplicate pages are on your own website
- Duplicate content is ranking in SERPs and people are visiting
- Hiding duplicate pages doesn’t hurt your site’s structure
Take this example:
A website audit reveals that you have two posts targeting the same keyword, and the posts have similar content. Both are ranking and driving traffic…
Redirecting one post to the other (which is better, up to date, and has better rnakings) will solve duplicate content issues without hurting traffic and rankings.
3. Consolidating content
When you have multiple posts covering similar topics, it is best to consolidate them to avoid duplicate content.
This happens when you’ve a fairly large blog with thousands of articles. You might create duplicate content unintentionally over time.

It’s a great way to avoid duplicate content on large blogs. Regularly merging and consolidating similar posts significantly improve ranking and optimises the crawl budget.
4. Content audit
Avoiding duplicate content on your site gets easier with regular site and content audits.
This helps you avoid creating and publishing new content that already exists on your blog and might lead to duplicate content.
Having a robust SEO content strategy is a guaranteed way to avoid duplicate content because you follow a systematic process of content creation which includes periodic content auditing.
The content strategy shows you what content you’ve published, how it’s performing, what needs to be updated, and what to create next.
A simple look at the editorial calendar will give insights into whether you’ve already covered the topic or not…
This proactive approach should be your top priority to avoid duplicate content in the first place!
5. Syndicate content smartly
Content syndication refers to republishing the same content on one or more websites for exposure, thought leadership, credibility, and other benefits.
Syndicated content across domains isn’t problematic and is a norm in the news and publishing industry. A single news from one source is republished by hundreds of other news sites.
You can syndicate content to reach new target audiences through different websites and it can be done in multiple ways:

But this be done carefully to avoid duplication content issues. Follow these best practices to avoid duplicate content and SEO problems with content syndication:
- Use canonical tags to avoid self-competition and dividing organic traffic
- Avoid republishing the exact same content across websites. Changing the target keyword, title, headings, and a few paragraphs is probably a good idea! (This helps you rank more than one article in SERPs without self-competition)
- Add a ‘no-index’ tag to content that you don’t want to get indexed. This should be used when you only want to reach readers of a specific website or publication
- Give credit to the original source with a link. This helps you set appropriate tags for search engines and readers
Conclusion
Unfortunately, duplicate content is inevitable. As your site grows, and depending on your CMS, duplicate content starts accumulating and it usually goes unnoticed (because it’s not always intentional).
It’s not easy to find duplicate content that’s created as a result of parameters on ecommerce sites or due to categories, tags, and archives for blogs.
Sticking with the best practices to deal with and avoid duplication on the same and different domains will help you avoid ruining rankings and your organic traffic efforts!
If you ever find yourself stuck with duplicate content SEO issues popping up on your site, then reach out to us!
At Growth Minded Marketing, we have the resources, tools, and experience that help us deliver the best SEO services to our clients including duplicate content management and removal.




Find out how our SEO management services can help your business grow in 2024